
|
|
Text Information Modeling and Analysis Group |
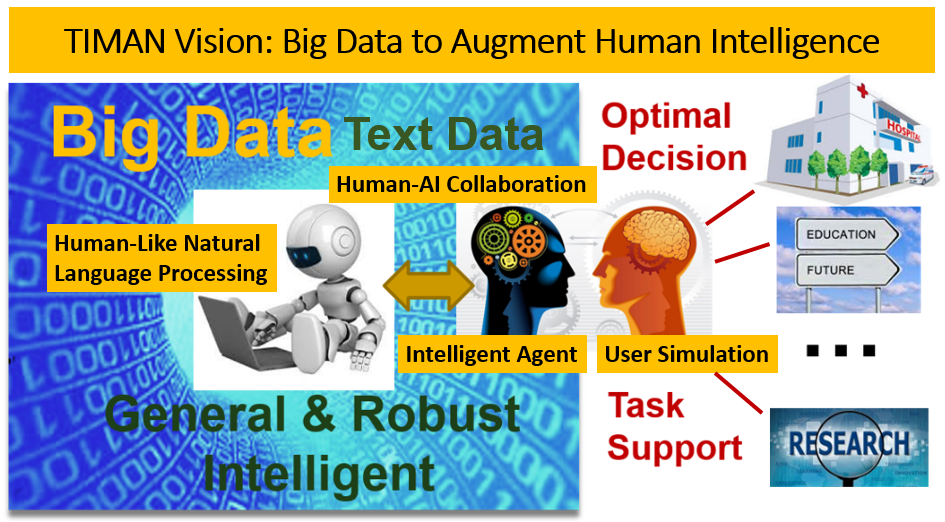
Our research uses techniques from multiple fields, such as information retrieval, natural language processing, data mining, and machine learning. We are especially interested in developing formal models, general intelligent algorithms, and general tools that can be used to support many different applications as well as using them to build innovative useful application systems in specific domains such as healthcare, medicine, online learning, and scientific discovery.
We emphasize optimization of human-AI collaboration and maximization of the combined intelligence of humans and AI systems. To this end, we study how to mathematically model and simulate users, which is required for both evaluating and training interactive intelligent systems. Leveraging user modeling and simulation, we study how to optimize sequential decisions for an intelligent agent to interact with users to support their tasks in a personalized manner while minimizing a user's overall effort. To enable explainable AI (XAI) and trustworthy AI, we are also interested in studying human-like natural language processing techniques, especially neuro-symbolic models. We apply general models and algorithms to develop specific intelligent task agents in multiple application domains such as healthcare, education, and scientific discovery. See the list of TIMAN projects for details about the projects that we have completed and our current projects.
Our research has been funded by many different sources, including government agencies (e.g., NSF, NIH, DHS, DOI, NASA, AFOSR, IARPA, DOE, FDA), industry (e.g., Microsoft, Google, Yahoo, IBM, HP, LinkedIn, Amazon, Intel), and private foundations (e.g., Alfred P. Sloan and Robert Wood Johnson).